Configuring AppSignal
First, you must configure your AppSignal integration or stand-alone agent to receive metrics from NGINX. If you configure your AppSignal integration with environment variables, you must setAPPSIGNAL_ENABLE_NGINX_METRICS to true.
If you configure your AppSignal integration with configuration files, or you use the stand-alone agent, you can follow the relevant instructions below on how to enable NGINX metrics for your application:
Ruby
Addenable_nginx_metrics: true to the desired environment in your application’sconfig/appsignal.yml file, for example the production environment:
Elixir
Addenable_nginx_metrics: true to your AppSignal configuration block, usually located at config/config.exs:
Node.js
AddenableNginxMetrics: true to your appsignal.cjs file:
Stand-alone agent
Addenable_nginx_metrics = true to your /etc/appsignal-agent.conf configuration file:
Configuring NGINX
The next step is configuring your NGINX server to send metrics to AppSignal. In most Linux distributions, the default NGINX configuration will include configuration files from a configuration folder, often located in/etc/nginx/conf.d. Save the following configuration to that folder as appsignal-metrics.conf:
Replace
127.0.0.1:27649 with the host and port where your AppSignal integration or stand-alone agent is listening for NGINX metrics.http block of your nginx.conf file:
server or location block contains an access_log directive, metrics for requests to that server or location will not be reported to AppSignal. To report metrics to AppSignal for those requests, you will need to add the following line inside the block:
Shell
Replace
127.0.0.1:27649 with the host and port where your AppSignal integration or stand-alone agent is listening for NGINX metrics.access_log directive inside the block will continue to work as before.
Configuring request groups
By changing the value of the$appsignal_group variable within a location or server block in your NGINX configuration, you can differentiate between different kinds of requests handled by your NGINX server:
Disabling metrics
You can use theaccess_log off directive to disable all access logs within a location or server block. Note that this will disable all access logs configured, not just those that are sent to AppSignal as metrics.
To only report metrics from specific location or server blocks, remove the following line from the appsignal-metrics.conf file, then add it only inside the specific location or server blocks that you would like to report metrics to AppSignal from:
Replace
127.0.0.1:27649 with the host and port where your AppSignal integration or stand-alone agent is listening for NGINX metrics.access_log directives in the surrounding server or http block. To enable those access logs again, repeat their corresponding access_log directive inside the location or server block that you added the above line to:
Magic dashboard
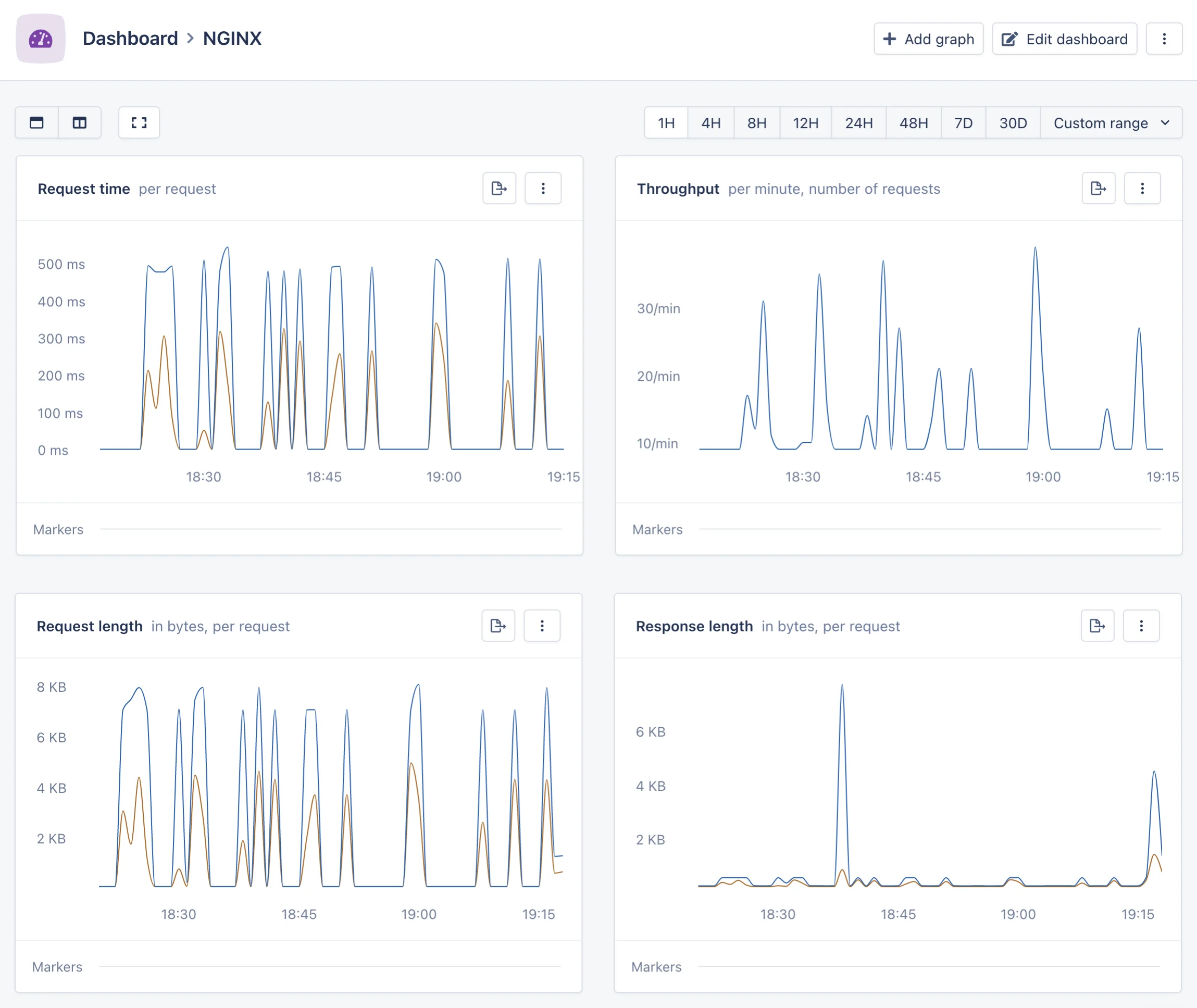
- Request time: the time taken by your NGINX server to respond to a request, as a per-minute mean and 95th percentile.
- Throughput: a count of the requests handled by your NGINX server.
- Request length: the length in bytes of the request received from the client by your NGINX server, as a per-minute mean and 95th percentile.
- Response length: the length in bytes of the response sent to the client by your NGINX server, as a per-minute mean and 95th percentile.
- Status codes: a count of the status codes of the responses sent by your NGINX server.
- Connections: a gauge of the connections currently being handled by your NGINX server, measured once per minute and segmented by the status of the connection.
- Upstream status codes: a count of the status codes of the responses sent by the upstream servers that your NGINX server proxies from.
- Upstream response time: the time taken to respond to a request by the upstream servers that your NGINX server proxies from, as a per-minute mean and 95th percentile.
- Upstream cache status: the status of the cache (such as
HITorMISS) when handling a cached request proxied from an upstream server.
Metrics
The following metrics will be sent to AppSignal from your NGINX server:nginx_status: A counter incrementing for each request handled by your NGINX server. Tagged by:status: The status code of the response.group: The request group, as configured in your NGINX server.hostname: The hostname of the server that handled the request.
nginx_request_time: A distribution of the time taken to respond to each request. Tagged by:group: The request group, as configured in your NGINX server.hostname: The hostname of the server that handled the request.
nginx_request_length: A distribution of the bytes received in the request from the client, for each request. Tagged by:group: The request group, as configured in your NGINX server.hostname: The hostname of the server that handled the request.
nginx_bytes_sent: A distribution of the bytes sent in the response to the client, for each request. Tagged by:group: The request group, as configured in your NGINX server.hostname: The hostname of the server that handled the request.
proxy_pass NGINX directive, the following metrics will also be present:
nginx_upstream_time: A distribution of the time it took to communicate with the upstream server. Tagged by:group: The request group, as configured in your NGINX server.hostname: The hostname of the server that handled the request.upstream: The upstream server that the request was proxied to.measurement: The specific time measured:connect: The time it took for the connection to be established.header: The time it took for the response header to be sent.response: The time it took for the full response to be sent.
nginx_upstream_status: A counter incrementing for each request proxied to an upstream. Tagged by:status: The status code of the response.group: The request group, as configured in your NGINX server.hostname: The hostname of the server that handled the request.upstream: The upstream server that the request was proxied to.
proxy_cache NGINX directive, the following metric will also be present:
nginx_upstream_cache_status: A counter incrementing for each request proxied to an upstream with caching enabled. Tagged by:status: The cache status for the request.group: The request group, as configured in your NGINX server.hostname: The hostname of the server that handled the request.
ngx_http_stub_status_module NGINX module enabled (as provided by most Linux distributions) then the following metric will also be present:
nginx_connections: The number of connections that your NGINX server is currently handling. Tagged by:hostname: The hostname of the server that handled the request.measurement: The specific number of connections measured:active: The number of active connections.reading: The number of connections where the request is being read.writing: The number of connections where the response is being written.waiting: The number of idle connections.