With Anomaly detection, you can configure Triggers to send notifications when a metric value goes over or dips below a threshold value. For example: When the error rate of an application goes over 5 % or free memory dips below 100MB.
Anomaly detection works by detecting changes in metric values on a minutely basis. When a threshold condition is reached, we will notify you of the new alert created by this event and notify you again when the threshold is no longer being reached.
To ensure you are being alerted at a time that suits you, you can define warm-ups and cooldowns to control when a new alert is opened.
Alert states
Alerts can have five different states:

When will I be notified?
After you’ve configured notifications, you will be notified when an alert goes into the open phase. You will be notified by any reminders you configured during that phase and when the Alert is closed.
Email alerts
Alert emails will include an overview of new alerts, reminders, and the status of other alerts that have yet to end.
Creating and configuring triggers
Anomaly detection can be configured per app in the “Anomaly detection” section in the app navigation. By default you will see the latest alerts created by triggers that you’ve configured for the app.
In the top navigation you can switch to the triggers page to create new and edit existing triggers.
You can create and manage Triggers from the “Anomaly detection” section of your application’s navigation menu.
 You can configure Triggers with a variety of metrics:
You can configure Triggers with a variety of metrics:
- Error rates
- Error (absolute) counts
- App throughput
- Performance of actions (slow actions)
- Queue time
- Host metrics
- CPU load
- Disk I/O
- Disk usage
- Load averages
- Memory usage
- Network usage
Warm-up and cooldown
You can configure warm-up and cooldown settings for each trigger, allowing you to define the time the system waits before opening and closing an alert.
Warm-up
It’s not recommended to use Anomaly detection and the Warmup feature to check
if services such as hourly/daily jobs and cronjobs are running.
Cooldown
Alerts opened by a Trigger are automatically closed when the threshold condition is no longer met. To avoid being overly notified, you can configure cooldown periods.
If you have configured a cooldown period for a Trigger, a new alert will not be created unless the Trigger’s conditions are met after the cooldown period has expired.
For example:
- An Alert is opened because the error rate is higher than 5%
- The error rate drops, so the alert is automatically closed.
- The trigger for the alert has a two-minute cooldown period.
- The error rate goes above 5% again.
- AppSignal will not create a new alert unless the error rate exceeds 5% after the cooldown period ends.
Some metrics require tags to be selected as well. For example, if you are sending a custom metric to AppSignal that has tags:
Then while creating a Trigger for this metric you need to select tags as well.

Missing datapoints as 0
By default, Triggers assume that a data point is sent every minute.
This may not be feasible in certain situations, such as incrementing a counter only if a specific action occurs. In such cases, you can use the option "When checked, we will treat missing datapoints as a value of 0". Enabling this option will cause the system to assume that a missing data point has a value of zero. This will help ensure the alert closes as expected if no data is received in the next minute.
Data processing
The metrics used by triggers to create alerts are not instantly processed when the metrics are sent from your application to AppSignal.
Your metrics data will go through multiple systems before it arrives at our processor. The data may also be sent from multiple servers that send data at different intervals.
The processor then waits* until all the data for a minute has arrived before processing that data and creating or updating alerts.
If you experience problems with the metrics being reported by AppSignal for Anomaly detection, ensure that your application’s servers are all reporting simultaneously by configuring them using NTP. Incorrect or different reported times for data sent by multiple app servers can result in Alerts never being opened or closed.
You can learn more about how AppSignal processes data for Anomaly detection and what this means for the alerts in our data life cycle documentation.
*: For more information on wait time specifics, consult our data life cycle page.
Managing incidents
You can view all alert incidents on the Anomaly Issues page in the AppSignal app. The Issues page displays an overview of all open alert incidents, ordered by their last occurrence, with columns for the anomaly:
- Name
- Status
- Assignees
- State
- Last state change time
You can also easily filter your incidents based on their state.
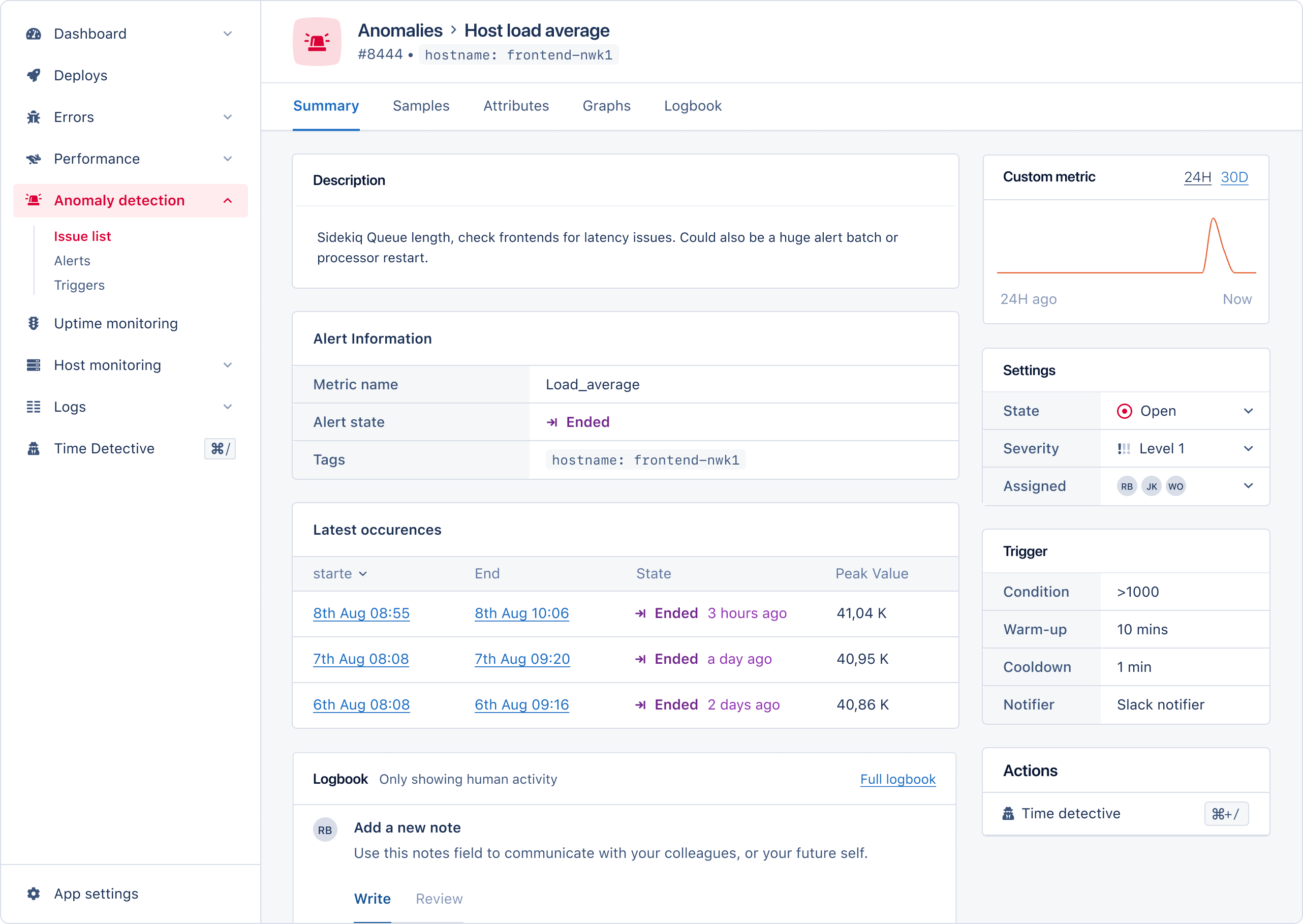
 To investigate an incident further, you can open the incident summary. Here you’ll find all the tools and information needed to investigate further the anomaly triggering your alert. On the summary page, you will have access to:
To investigate an incident further, you can open the incident summary. Here you’ll find all the tools and information needed to investigate further the anomaly triggering your alert. On the summary page, you will have access to:
- Alert information: The metric name, alert state, and tags of the alert.
- Occurrence frequency graph: A visual representation of the alert’s occurrence.
- Incident Settings: Ability to close the alert, set its severity, and assign it to a team member.
- Trigger Information: The conditions required to trigger the alert.
- Latest occurrences: A table of the most recent occurrences, with their start/end time, state, and peak value.
- Logbook: A logbook for logging important alert information about this alert for your team or future self.
- Access to the Time Detective: Use the Time Detective tool to view the state of your application when the alert last occurred.
All of these features are easily accessible in our intuitive UI: